
Detta är en beskrivning av hur vi på Johannas Stadsodlingar och Concinnity tillsammans har byggt Johannas Akvaponi Pilotanläggning. Vi vill dela med oss hur vi har gjort och tänkt. Det är ganska mycket att tänka på, så det blir flera inlägg för att täcka det mesta.
- Del 1 – att starta, förkunskaper
- Del 2 – design
- Del 3 – bygglogg
- Del 4 – vattenkvalitet och näringstester
- Del 5 – produktionsspårning
- Del 6 – integration med blockkedja (denna blogpost)
Cultivation Management Platform
De digitala system vi byggt har grundats på den vision vi satte i början på projektet som vi kallar Cultivation Management Platform (CMP).
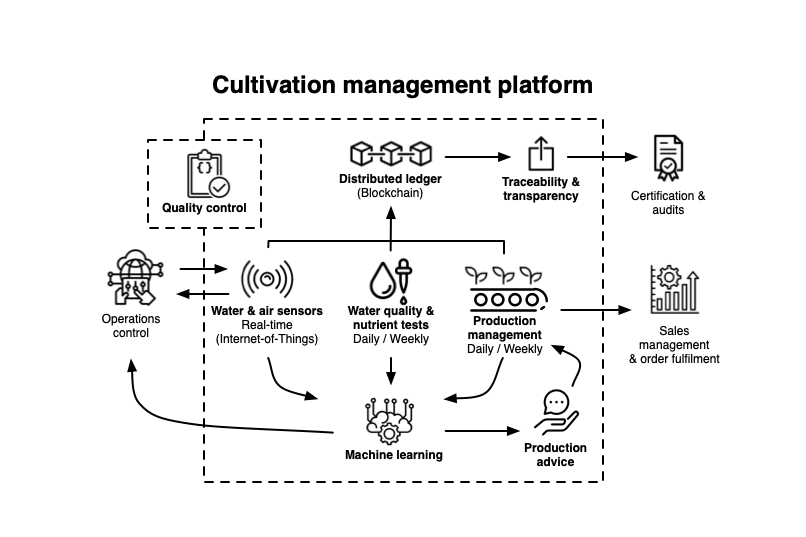
CMP kan delas upp i fyra delar:
● Vattenkvalitets- och näringstester (Water quality & nutrient tests)
● Vatten-, luft- och automationssensorer (Water & air sensors)
● Produktionsspårning (Production management)
● Distributed ledger / blockkedja (Blockchain)
I detta avsnitt beskriver vi arbetet med distributed ledger / blockkedja (Blockchain).
Vi har byggt ett system som demonstrerar hur man kan använda en distributed ledger. En distributed ledger är en databas som kan delas mellan många olika parter, där alla parter gemensamt kontrollerar informationen och där all data som lagras är ”permanent”, dvs den går i princip inte att ändra på i efterhand. Det kan låta väldigt opraktiskt, men vad man istället gör när data behöver ändras är att man refererar till den ursprungliga informationen och lägger till en ändring. På så vis blir alla förändringar av databasen synliga för alla parter. Blockkedjan, blockchain, är den underliggande teknologi som används för att garantera att informationen som lagra i databasen inte går att ändra i efterhand. (Detta är naturligtvis en mycket förenklad beskrivning av hur en distributed ledger fungerar i praktiken!)
Vi har fått tillgång till IBM Food Trust(IFT) för att bygga vår blockkedjedemonstration i samarbete med IBM och Atea som är en svensk IBM-partner. IFT är en distributed ledger baserad på open-source programvaran Hyperledger som implementerar en blockkedjebaserad databas. IFT tillhandahåller API:er för att lagra data i och hämta data från blockkedjan.
Systemet i stora drag
Data från vårt produktionsspårningssystem transformeras för att “passa” i IFT och skickas dit för lagring (XML Gen). Detta sker regelbundet med automatik så att data i IFT är synkroniserad med produktionsspårningssystemet. En andra del, Data display, hämtar information från IFT. Vi presenterar en lista över alla skördar som gjorts och man kan välja en skörd för att få en detaljerad beskrivning av alla stegen som just denna planta gått igenom på sin väg från frö till färdig produkt.
Data
Den data vi lagrar i IFT är baserad på kärnan av den data vi genererar i produktionsspårningssystemet. Detta innefattar varje steg i spårningen av en planta från groddning till skörd. All data som lagras i IFT får unika ID:n som vi sedan använder när vi hämtar information ur IFT i klientappen (Data display). På så sätt har vi kunna bygga klientappen så att den inte är beroende av någon del av den ursprungliga informationen från produktionsspårningssystemet utan all information kommer från IFT.
Implementation
Systemet består av två delar. Den första delen, XML Gen, hämtar data från produktionsspårningssystemet och efter att ha transformerat denna data till XML skickas den till IFT för lagring i blockkedjan. Den andra delen, Data display, hämtar data från IFT och presenterar den som webbsidor. Denna del hämtar informationen från IFT, där data levereras i formatet JSON, och efter transformation av denna data skapar vi vyer som webbsidor. Observera att Data display är helt oberoende av den ursprungliga informationen i produktionsspårningssystemet. Den köras som en helt oberoende tjänst eftersom den hämtar all nödvändig information från IFT.
XML Gen
Det visar sig att de händelser vi skapar i produktionsspårningssystemet låter sig översättas till liknande händelser i IFT. Den data som vi på så sätt lagrar i IFT är baserad på GS1 EPCIS Standard 17 . Vi har skapat en XML-mall för varje typ av händelse som vi sedan fyller i med aktuell data varefter den laddas upp till IFT. Utöver denna information registrerar vi varje kombination av frön och leverantörer vi använder som produkter i IFT, samt en plats, gården där vi driver akvaponin. Dessa dokument är baserade på GS1 GDSN Standard 18 och data i IFT skapas på liknande sätt från en kombination av XML-mallar och data från produktionsspårningssystemet. IBM har en wiki på GitHub med information om hur de använder dessa standarder, om API:erna mot IFT etc som vi haft mycket nytta av.

IFT definierar ett antal olika händelser och vi har använt tre typer för att registrera vår data, Commission, Observation och Transformation. Dessa tre händelser är definierade i EPCIS. Commission används när en ny enhet av en viss produkt ska registreras. Vi använder denna händelse för att registrera Groddningshändelsen. Observation används för att registrera en förändring hos en existerande enhet. Denna typ av händelse använder vi för att registrera händelserna Stickling och Skörd från produktionssystemet. Slutligen använder vi en Transformation för att registrera våra händelser av typ Planta. En Transformation “gör om” en produkt till en annan. I vårt fall transformerar vi en stickling till en planta. Detta modellerar bra den praktiska förflyttningen av sticklingarna från odlingsbrickan till flottarna där de växer till färdiga plantor.
Data display

Data display hämtar data från IFT via ett flertal API-anrop (endpoints). Med hjälp av anropet “/products” får vi en lista på alla registrerade produkter. Utifrån denna lista kan vi sedan hämta detaljer om varje skörd. Sedan hämtar vi fullständig produktdata för varje skörd så att vi kan visa vilken typ av planta och leverantör den består av. Slutligen använder vi anropet “/trace” för att få “historiken” för varje skörd, dvs de fyra händelserna i plantans liv. På så sätt kan vi visa den fulla historiken för varje skördad planta.
Diskussion
Denna prototyp är mycket “minimalistisk”, men den innefattar ändå de fundamentala delarna i ett blockkedjebaserat spårningssystem. Vi skulle kunna leverera våra produkter med en märkning i form av en streck- eller QR-kod, som länkar till en webbsida där köparen kan få den fulla historiken av hur plantan kom till.
[track’n’trace image?]
I dagsläget saknas information om vad som hänt med produkten från det att den skördats till dess att kunden har den i sin hand, men om man spårar även denna del skulle kedjan kunna förlängas och hela förloppet kunna finnas dokumenterat i blockkedjan i IFT. Den delen av spårningen skulle kunna göras av ett speditionsföretag och/eller av butiken som säljer produkten. De olika parterna skulle lagra “sin del” av informationen var för sig i blockkedjan samtidigt som kunden kan se hela det resulterande händelseförloppet.
I nästa inlägg så tittar vi närmare på lärdomar från pilotsystemet som vi byggt.
Texten i detta inlägg är licensierad under Creative Commons BY-NC-SA International.